
Contradiction detection: why hybrid approaches outperform AI alone
AI can identify candidate contradictions in requirements, but language understanding alone produces too many false positives for engineering quality gates. This is why hybrid approaches , combining semantic search, deterministic validation, and structured evidence is the only path to precision at scale.

Photo by ThisIsEngineering on Pexels
Over the past decade, we’ve reviewed thousands of requirements across connected vehicle platforms, software-defined vehicle programmes, and supplier specifications. We’ve seen a pattern appear. Teams rarely fail because they lack requirements. They fail because requirements that appear reasonable in isolation become contradictory when viewed together and nobody caught it in time.
This is not an oversight. It's an issue of scale.
The gap between similarity and contradiction
When people picture contradictory requirements, they tend to imagine something obvious:
REQ-001: The system shall transmit vehicle speed every 50ms.
REQ-002: The system shall transmit vehicle speed every 100ms.
A clear conflict. Same behaviour, different constraint. Straightforward to catch in a document small enough to read twice.
Real contradictions rarely present this cleanly. Consider a pair from a functional vehicle communication specification:
REQ-0112: The communication module shall transmit the speed signal upon invocation of the single-signal send interface.
REQ-0521: The communication module shall transmit aggregated signal frames upon invocation of the signal group send interface.
A purely semantic analysis may flag these as contradictory. Both describe transmission behaviour, both reference the communication module, both use similar vocabulary about signals and invocation.However, they describe different functions, different execution paths, and different operating contexts. They are not contradictory.
This distinction is what makes contradiction detection genuinely difficult. Finding conflicts is not just a language task. It is logic that presents itself in language, and the two require fundamentally different approaches to handle reliably.
Why the geometry of large specifications breaks manual review
A 100-requirement specification is reviewable by most people. A 10,000-requirement specification is a different kind of problem. The number of unique pairings grows quadratically, 10,000 requirements produce roughly 50,000,000 possible pairs. Add a second specification from another supplier and the number climbs into the billions.
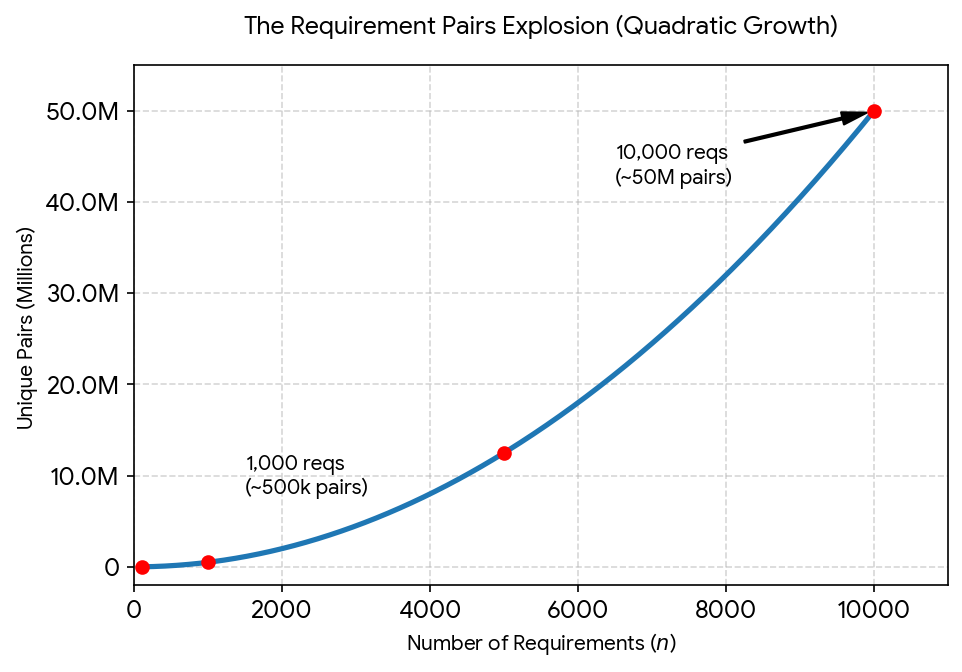
Human reviewers work through documents section by section. Contradictions frequently cross section boundaries: a system requirement conflicts with a software requirement written six months later by a different team, or an interface specification quietly contradicts a compliance obligation buried in a supplier deliverable. The contradiction exists whether anyone finds it or not.
As software-defined vehicle programmes bring together requirements from hundreds of suppliers and subsystems, this problem compounds. The specifications don't just grow larger. They grow more interdependent, across organisations that don't always communicate the decisions embedded in their requirements.
The challenge isn't reviewer competence. It's geometry.
What keyword matching gets wrong
The earliest automated tools relied on opposing term detection. Find "enable" near "disable". Flag "increase" against "decrease". Raise an alert where "maximum" and "minimum" appear in proximity across two requirements.
Fast, and computationally cheap. Useful for an early pass on a small document.
Engineering language breaks this approach quickly. Consider:
REQ-A: The system shall disable charging when battery temperature exceeds 60°C.
REQ-B: The system shall prevent charging when battery temperature exceeds 60°C.
A keyword-based system sees "disable" and "prevent" as candidate opposing terms and raises a flag. An engineer reads two sentences expressing identical intent. Precision falls immediately, and it keeps falling as document size increases and specification language becomes more domain-specific.
The practical result is that teams receive a report containing hundreds of flagged pairs, most of which are not actual conflicts. Engineers review the first dozen, find them unconvincing, and stop reading. The tool is left running but its output is treated as background noise. That outcome is worse than running no tool at all, because it creates the administrative illusion of automated review without the safety of it.
Where LLMs introduce a different problem
Modern AI analysis takes a different approach. Instead of matching terms, large language models attempt to understand meaning. This catches relationships that keyword systems miss entirely — a genuine improvement in coverage.
The problem is probabilistic behaviour. The same requirement pair can receive different assessments depending on prompting strategy, context window placement, or model version. That variability is manageable in some contexts. In safety-critical engineering, it creates a reproducibility problem. If running the same analysis twice produces different findings, the output cannot be treated as engineering evidence.
More fundamentally, LLMs often struggle to distinguish between four relationship types that can exist between two requirements: similarity, dependency, duplication, and contradiction. These are not the same thing. A requirement that duplicates another is not necessarily in conflict with it. A requirement that depends on another is not contradicting it. When analysis conflates these categories, it generates false positives, and false positives accumulate.
As other analysis of AI-powered engineering tools has shown, many products in this space share a structural weakness: their apparent effectiveness depends on assumptions about model consistency that hold in demos but degrade in production across varied specification formats, domain vocabularies, and document sizes.
An engineer who opens a contradiction report and finds 80 findings, 60 of which are debatable, that is not a detection tool, its just another review activity.
Why precision matters more than volume
Most discussions about AI and automated analysis focus on recall: how many issues did the system find?
In engineering quality gates, precision usually matters more.
A tool that identifies 100 findings with 20% accuracy is a burden. Teams learn to treat the output as background noise, and trust erodes. A tool that identifies 20 findings with 90% accuracy becomes something engineers actually use, because experience tells them the findings are worth investigating.
This sharpens considerably when contradiction detection feeds into development workflows. A quality gate that generates excessive noise becomes another checkbox to tick and bypass. A quality gate that surfaces high-confidence conflicts, before they propagate downstream into supplier deliverables, test campaigns, or certification evidence. It prevents rework at the stages where rework is most expensive.
One creates work. The other prevents it.
How hybrid approaches change the equation
The most effective contradiction detection systems work in layers rather than treating the problem as a single-pass analysis.
A semantic layer performs the broad search: scanning large specifications for candidate requirement pairs that appear related in meaning, subject matter, or scope. This is where AI adds genuine value — identifying cross-chapter and cross-document relationships that no reviewer could manually trace across a million-pair comparison space.
A deterministic rule layer then validates the candidates. Instead of asking whether two requirements look similar, it asks whether both can logically be true simultaneously. This layer catches numeric constraint conflicts and filters out cases like the REQ-0112 example above, where surface similarity conceals functional independence. The rule logic is inspectable, consistent, and version-stable.
Finally, structured evidence generation produces findings that engineers can evaluate and act on: the affected requirement IDs, the specific conflicting statements, the rationale for the conflict classification, and a confidence level. Not a suspicion. Evidence.
WYZER Detective's Sherlock engine applies this architecture. On a 1,578-requirement specification, it detected 202 duplicate candidates — 12.8% of the total — while returning zero false conflicts across the genuinely independent requirements. The single genuine contradiction it surfaced was the REQ-0112/REQ-0521 pair described earlier: two requirements separated by 400 entries in the document, conflicting on signal transmission scope in a way no section-by-section review would have connected.
Resolving it required more than identifying the pair. The requirement relationship graph exposed every neighbour sharing semantic proximity with both requirements — signal buffering constraints, transmission timeout obligations, error handling paths downstream. Clarifying the scope of REQ-0521 alone would have quietly invalidated three dependent requirements that referenced grouped signal behaviour. The visual neighbour map made those cascading effects visible before any change was written, which is what allowed the team to resolve the original conflict without introducing new inconsistencies in the process.
The engine handles specifications from a few hundred requirements up to the 100,000 range, processing text, tables, and embedded diagrams alongside written requirements.
The tradeoff is honest: the rule layer requires domain knowledge to configure well, and coverage across new specification types expands incrementally rather than immediately. That's a real constraint. The benefit is reproducible, with auditable findings with low false-positive rates. This is worth the investment for programmes where downstream errors are expensive.
What ISO 26262 actually requires from a finding
Precision matters for a reason that rarely surfaces in discussions about AI-assisted review: regulated industries require documented evidence.
ISO 26262 demands traceability, justification, and documented decision-making. A contradiction finding that enters a quality management system must be reviewable months or years after the original analysis. A safety assessor needs to understand what was flagged, why it was flagged, and why the engineering team accepted or rejected the finding.
"The AI thought they conflicted" satisfies none of those requirements.
An audit-ready finding includes the affected requirement IDs, the verbatim conflicting statements, the specific logic explaining why the conflict was classified as a contradiction, supporting evidence, and a confidence classification. This structure allows engineering teams to make and record defensible decisions, and to demonstrate to auditors that the analysis was not a black-box opinion but an inspectable process. For ISO 26262 work-products, that distinction can determine whether evidence is accepted or challenged during assessment.
The combination that actually works
The conversation around AI in engineering often gravitates toward replacement. Will AI replace review teams? The question is understandable but it tends to frame the problem wrong.
Large language models search broadly and cheaply across volumes of text that no human team could process at speed. Deterministic logic enforces consistency and produces repeatable, inspectable results. Experienced engineers apply domain context, identify edge cases, and make the programme-level judgement calls that neither AI nor logic can substitute for.
The systems that perform best combine all three — in that order. AI searches broadly. Deterministic logic validates. Engineers decide.
Contradiction detection at engineering scale isn't about finding more issues. It's about finding the right ones, with enough evidence to act on them, before they become expensive. That's a precision problem, and precision requires more than language understanding alone.
That is why WYZER exists.